Onboarding Payroll with Machine Learning
Part I
The Problem
Description
ADP had a large number of existing clients and new logos (~60-100) slated for migration to one of our newer payroll engines within 9 months. Each client has unique needs and takes roughly 2-3 months to onboard, and our implementation team had only 5 members.
Business Goals
- Successfully onboard up to 100 clients for payroll within 9 months.
- Ensure client satisfaction throughout the onboarding process.
Challenges
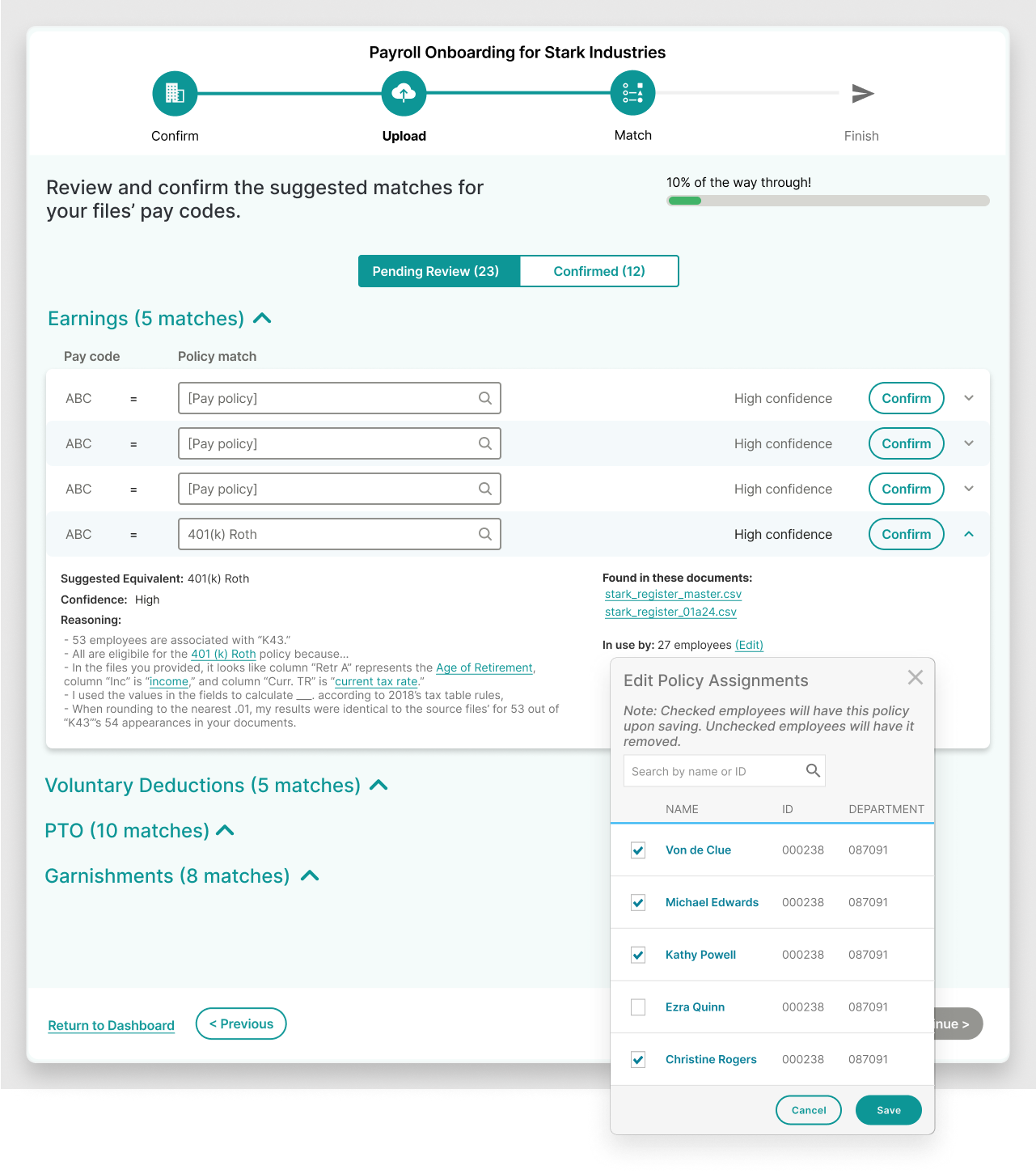
By far, the most time consuming aspect of onboarding is the mapping of pay codes from the old system to the new. A pay code is an, often arbitrary, 3-character code that represents a single pay policy in a payroll. Matching them is a complex manual process involving trial and error and data entry that’s prone to costly human error.
The Solution
Train a machine learning model on a large data set of manually mapped payrolls with the goal of it taking over the manual process for faster and more accurate output.
My Involvement
From inception to launch, I worked closely with data scientists to determine evolving feasibilities and workarounds while handling all aspects of UX research, UX design, and technical handoff as an embedded scrum team member.
Part II
Objectives
Business Needs
Meet the deadlines communicated to clients for their first payroll run.
User Needs
Streamline the pay code conversion process for ease of use and accuracy.
Team Needs
Within one month of starting this project, its product owner left the company and was not replaced for nearly a year. 😮
Part III
Research
Methods
SME Interviews
Met with small groups of data scientists and users throughout the design process to ensure alignment as the tech progressed.
Comparative Analysis
Assessed patterns used by other internal tools with similar stories for ideation and UX continuity.
User Testing & Analytics
Refined design decisions via testing with clickable prototypes.
Peer Review
Refined copy writing.
User Persona

User Journey
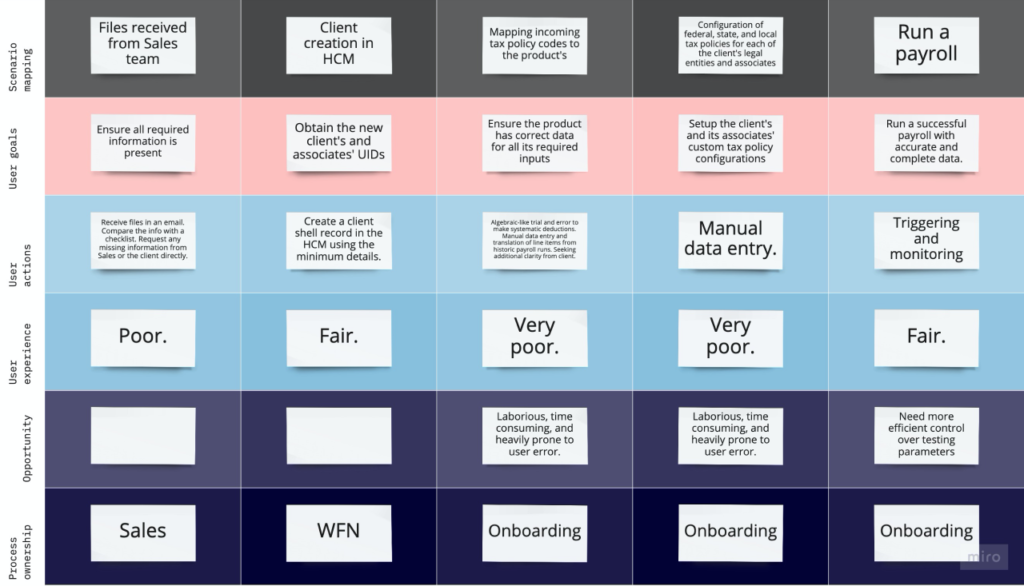
Part IV
Design
Technical Limitations
Creative Solutions
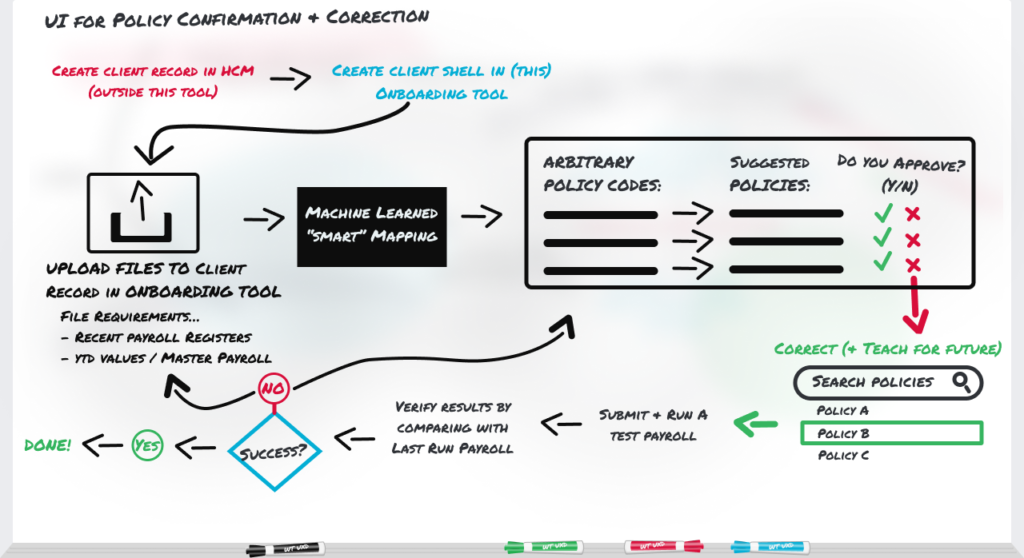
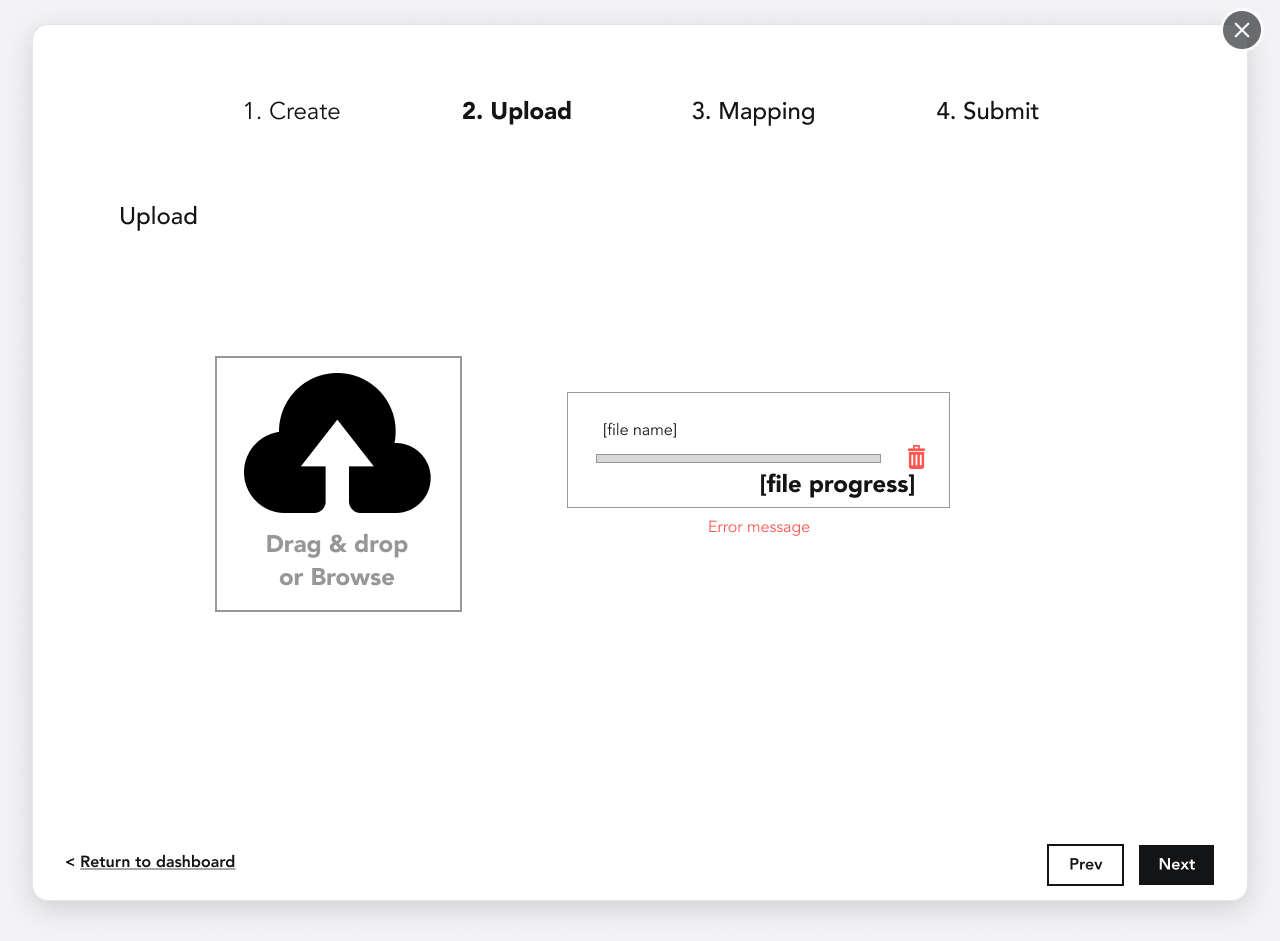
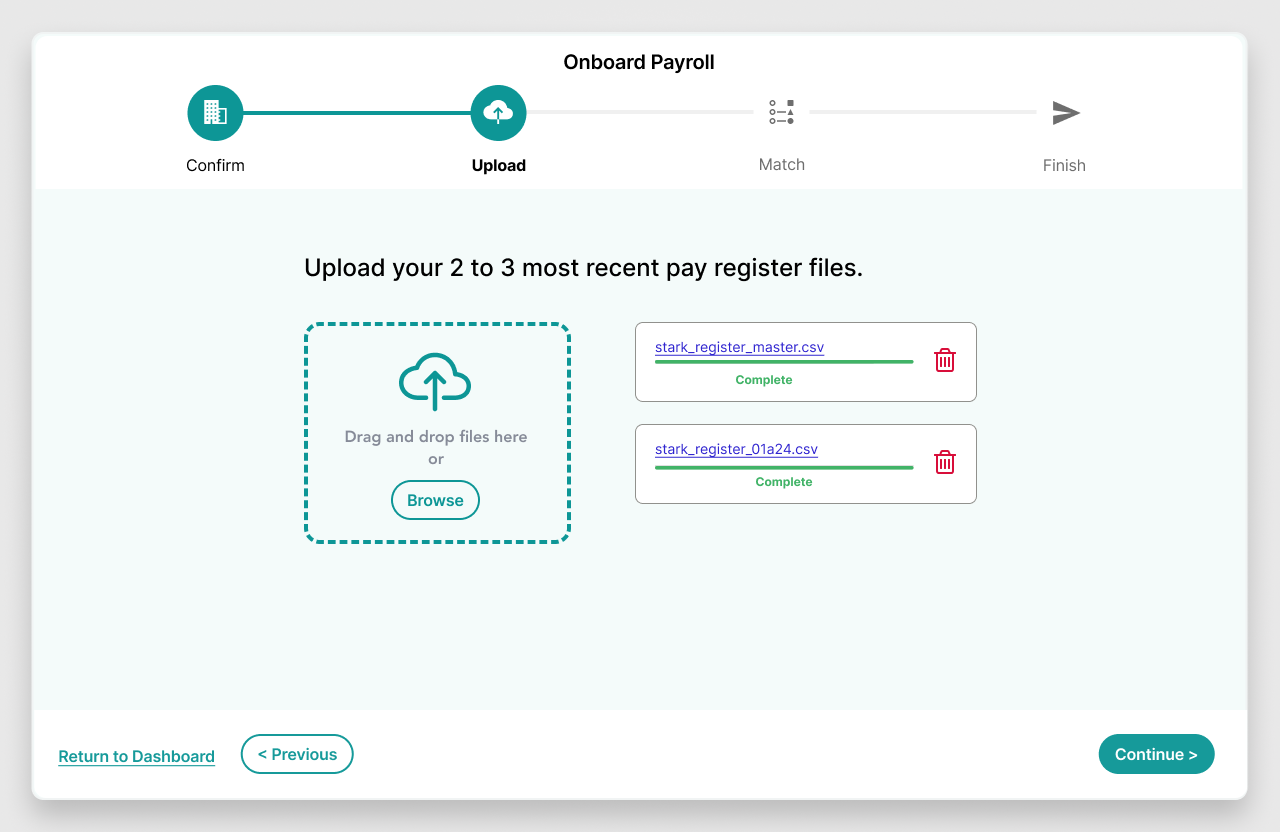
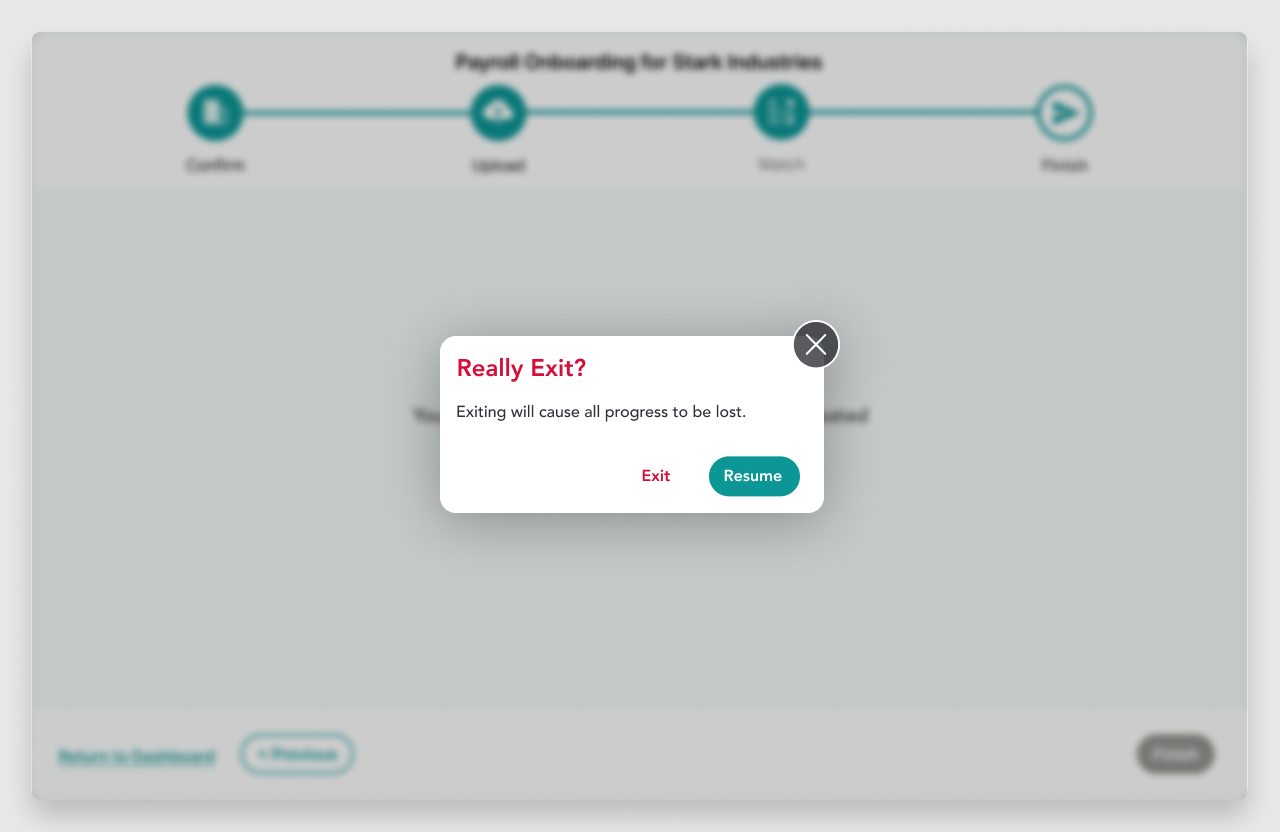
1. The UI didn’t technically have a database of its own. As a result, users wouldn’t be able to save their progress for later.
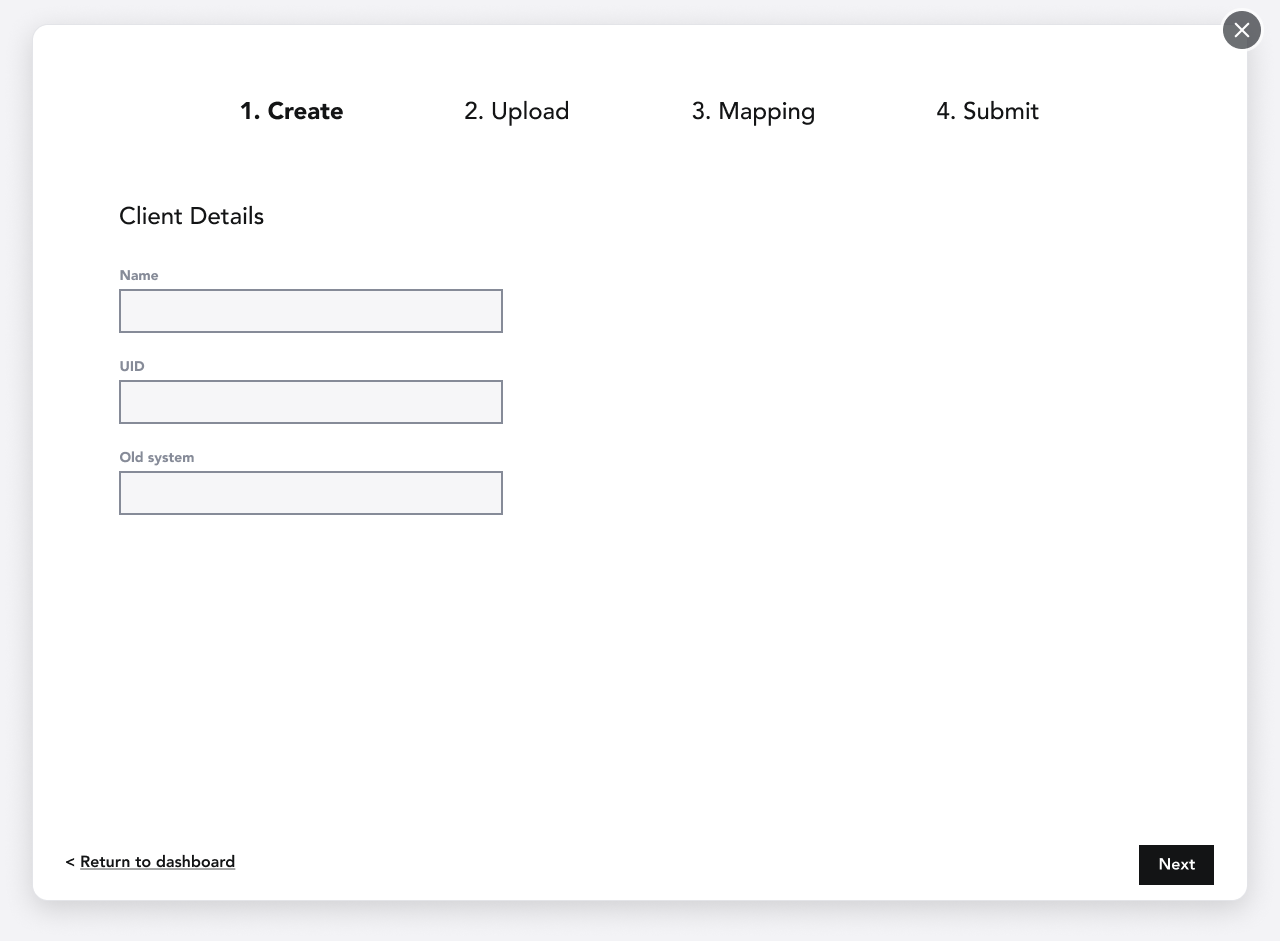
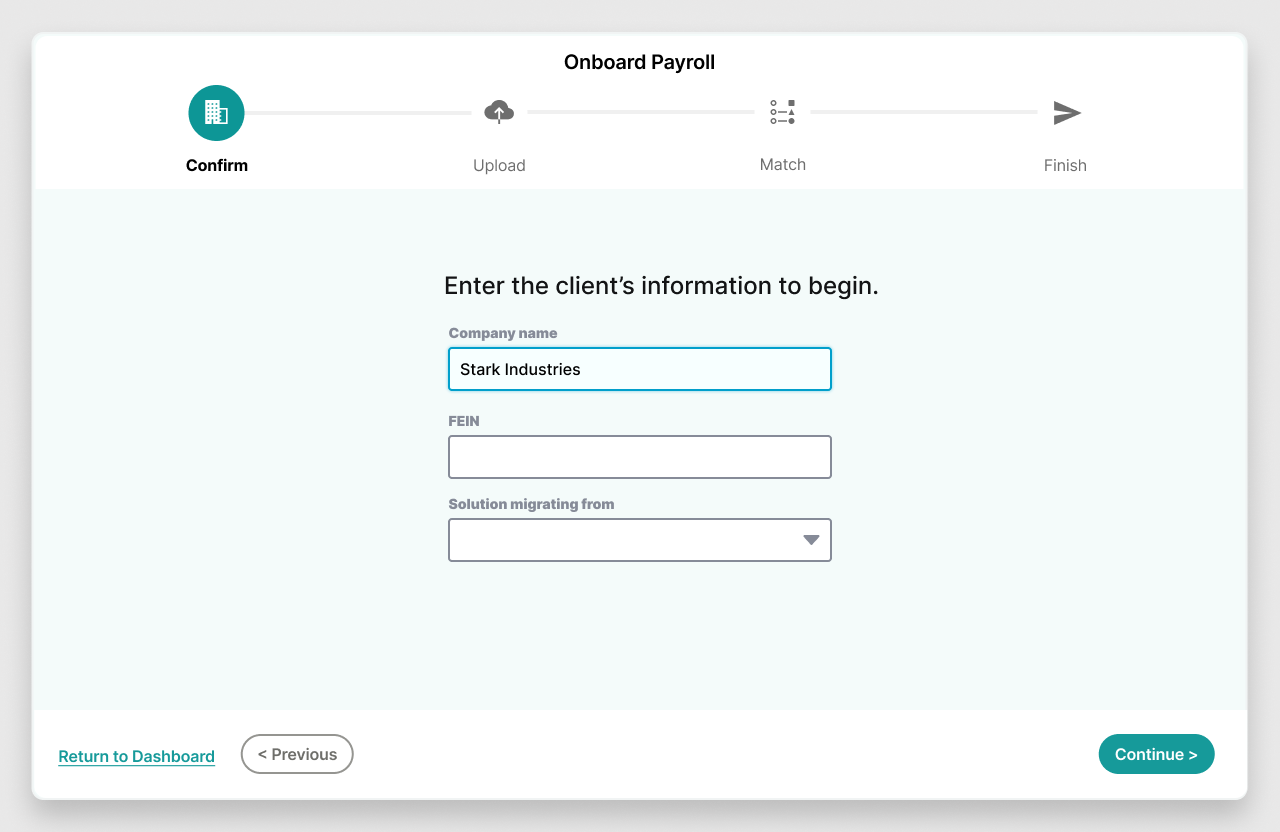
1. I designed the solution to prevent fatigue and give the user confidence in their ability to finish in one sitting, partly by breaking it down and making user input as simple as possible. For example, I was able to have the required UID field for the client selection (first screen) changed to FEIN, because I knew FEIN was also unique and it was something the user already had on hand. I also added a small progress tracker per research.
2. Users admitted to automation features having a poor track record at the company, and were reasonably slow to trust the machine’s suggestions.
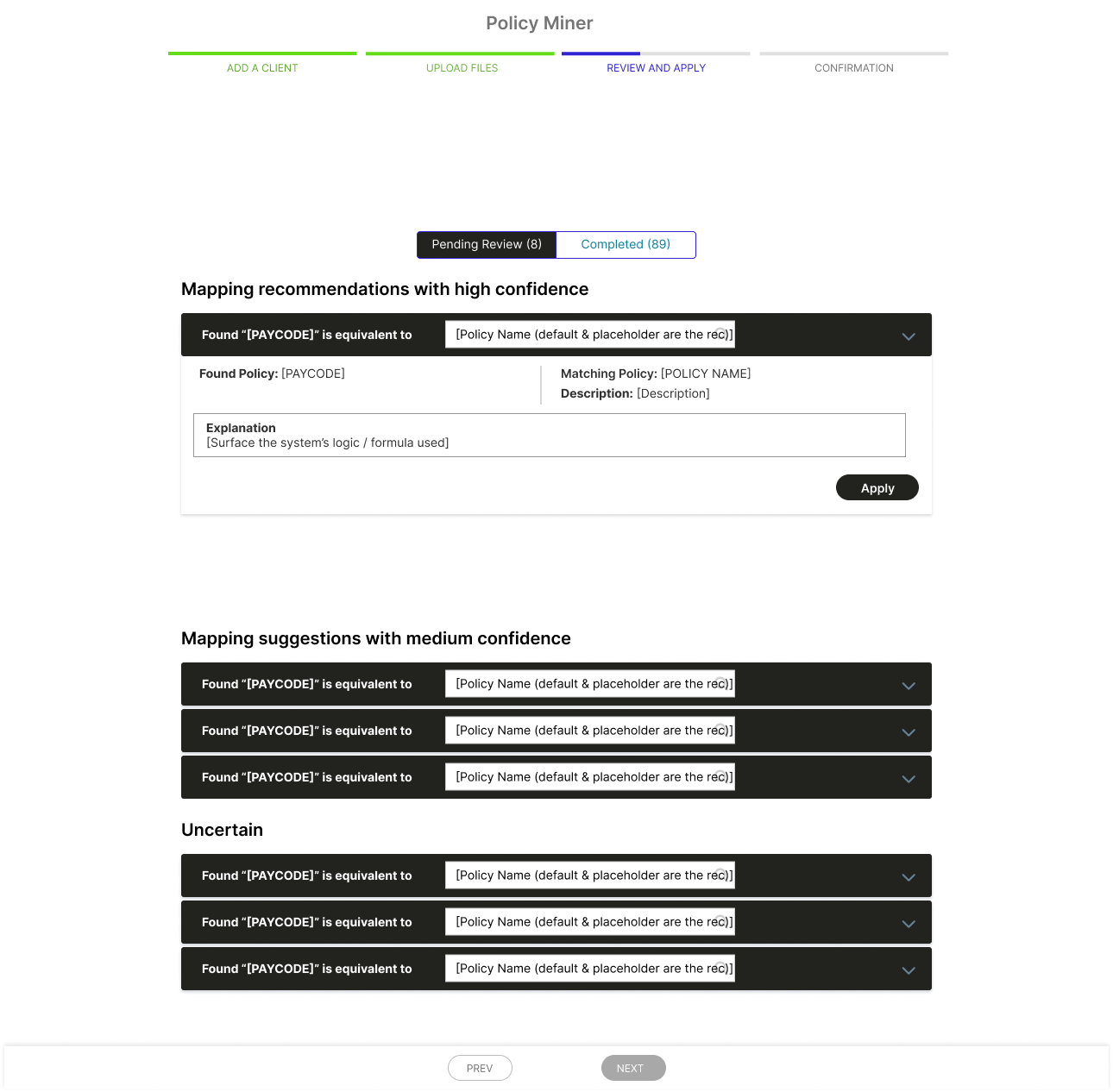
2. The machine wasn’t always 100% accurate, but I still wanted it to build trust with the users via transparency. I didn’t want their perception when it was wrong to be that it was unpredictable, erratic, or “hit or miss.” By revealing when the machine’s confidence in its own suggestion was low, it could still build trust with the user if wrong, because it was at least right about possibly being wrong.
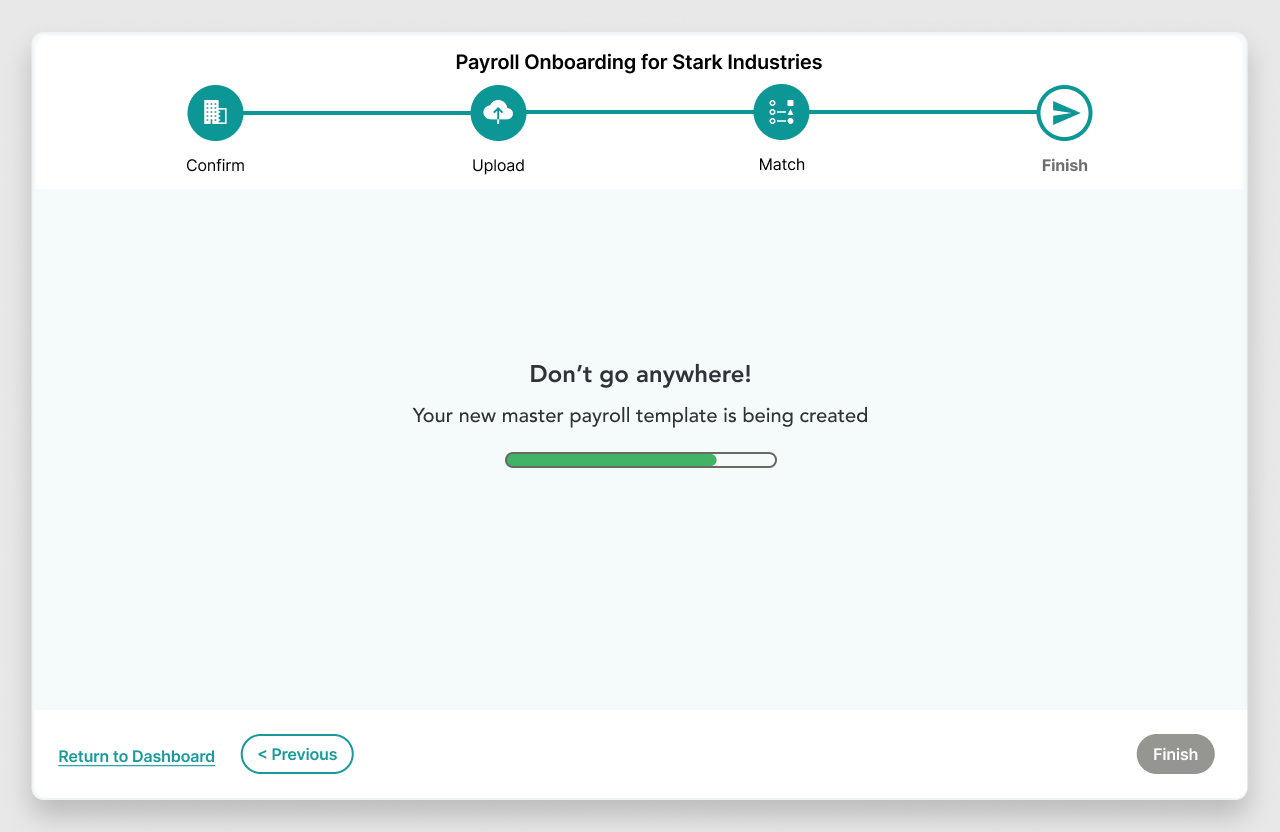
3. Data was processed externally in a sort of “black box,” then returned. This meant limited transparency into its progress for the user.
3. I was able to find out roughly how long a file’s processing could be expected to take based on previous files of the same size. This allowed us to offer a pseudo progress indicator, which was better than the alternative.
4. The more payroll files the user provided the more accurate results they would typically receive from the system. This meant we had to plan for an unknown number of file inputs.
4. I designed a new drag and drop multi-file uploader component and had it added to our design system for widespread usage.
5. Initially, we had planned to surface the system’s confidence level in its “guesses” on a scale of 1-100, but this was later deemed unfeasible. Without a score, the user may be prone to scrutinize all suggestions equally, contributing to fatigue.
5. I was able to retrieve a binary confidence score from the system to basically indicate whether the system thought it could be wrong. That way, I could still categorize/group them in a way that was adequately informative to the user.
Technical Flow
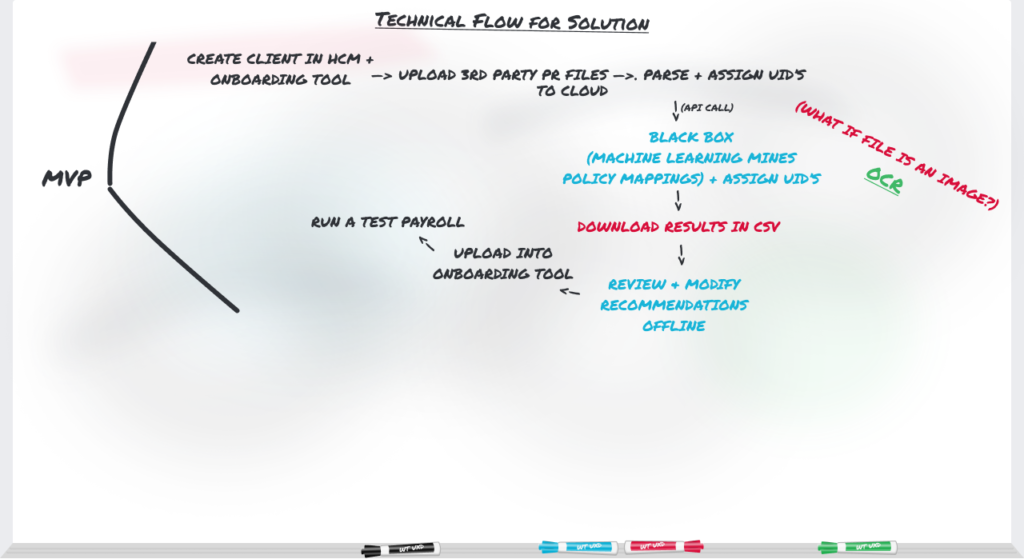
User Flow
{kind=link}
{kind=link}
{kind=link}
Part V
MVP Solution
Click each image to view.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
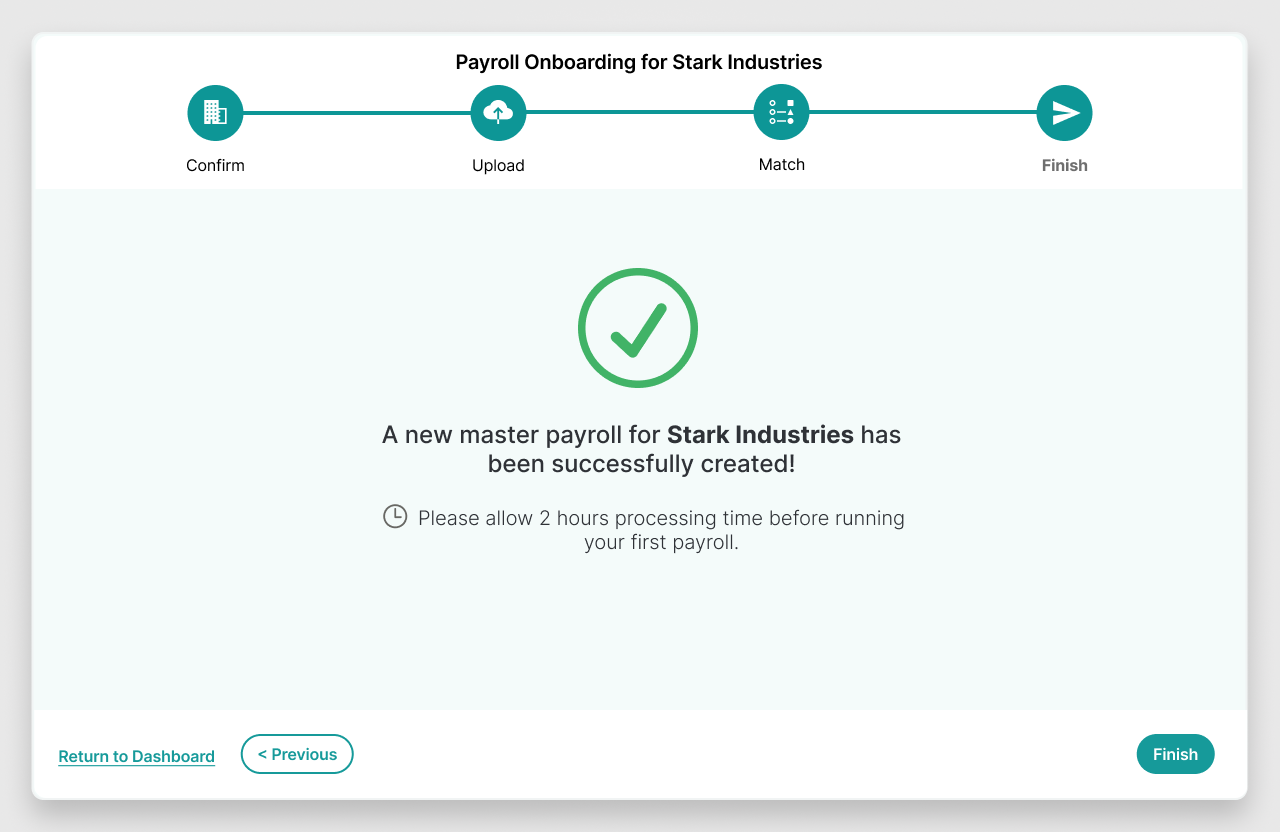{kind=link}
Part VI
Conclusion
Results
This tool reduced average onboarding time from 3 months to 2 weeks. With 2 new additions to the implementation team, we were able to effectively and successfully meet our clients’ expectations.
Future Considerations
- When user confidence is up, a multi-select functionality allowing users to confirm policies in bulk.
- Integrating OCR technology to further streamline accurate data entry of client-provided source files that were formatted as images.
- Setting up a secure database so that users can save their progress.
- A “save for later” status option for pay codes.
- Supporting clients completing this process themselves.
- Search functionality on the matches table.
Retrospection
This was my first project at ADP and consequently my introduction to payroll. It was also ADP’s first attempt to implement machine learning into a product at this scale, so this project had a lot of unknowns. There was a lot of information to process as a newcomer and a need to establish rapport quickly. My background in independent consulting made these challenges familiar to me and a little easier.
Despite not having a product owner for the majority of the project, I was proud of how we were still able to drive the project forward as a team.
If I could go back and change things, I would have pushed harder for more meetings with all implementors at once earlier, as some of their individual opinions and preferences differed significantly. When in the same room, however, they were able to reach shared consensus.